Java16で導入されたRecordですが、Java17リリースによりこれから一気に使われていくことかと思います。
Java17雑感で「データクラスを新しく作るならRecordを使ってみる」とか書いたんで「よしRecordを使おう!……ところで何気にしなきゃなんだっけ?」な私向けに、現時点で「これくらい知っとくといいんじゃないかな」ってことを書いておきます。だらだら書いたんで順番とか内容の濃淡がひどいかもしれない。
ちゃんとした知識
- JEP 395: Records
- Java Language Specificationの8.10. Record Classes
- Java Object Serialization Specificationの1.13 Serialization of Records
- GitHub openjdk/jdkのjava/lang/Record.java
とか。
あと、うらがみさんとこの「Javaのレコードについてメモ」
・・・・あれ、気になって調べたことが全部書いてある。まいっか。
書き方
record EmptyRecord() { }
record 名前 (レコードコンポーネントのリスト) {ボディー} ですね。ちゃんとしたのは言語仕様の方を。
空っぽでも () とか {} とかは必要。空のRecordの存在意義は知りませんが。
素直に書くとこんなの。
record Point(int x, int y) { }
シンプルで良い。けど { } がちょっとダサい。なくしたらセミコロン書かなきゃいけなさそうだし、仕方ないか(そんな理由じゃないはず)。
recordって名前はパッケージ名とか変数名とかには使える。- クラス名には使えない(Java14以降)
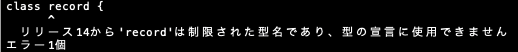
- 小文字クラス名とかやらないだろから問題ないでしょ。
- クラス名には使えない(Java14以降)
int x, int yとかを「レコードコンポーネント」と呼ぶらしい。- 呼び方は個人的に一番重要なとこだったりする。
record宣言で書くのは「レコードコンポーネント」であり、フィールドでもプロパティでもない。
- レコードコンポーネントに対応したコンストラクタ(CanonicalConstructor)とフィールド、アクセサメソッドが自動的に作られる。
- アクセサメソッドは自分でも定義できる。
- フィールドは
staticだけ。インスタンスフィールドを書いたらコンパイルエラー。 - 他のメソッドは好きに作れる。
- インスタンスフィールドを作れないのは地味に制約になるかも。
- コンストラクタも好きに作れる。
- CanonicalConstructorも作れる。型と名前をレコードコンポーネントに合わせる必要がある。
- CanonicalConstructorを呼ぶようにしなきゃいけないってくらい。
super()は呼べなかった。
- あと
nativeメソッドは書けない。書かないからいいけど。
CanonicalConstructorとかコンストラクタがちょっと特別なくらいで、他は難しい構文でもないと思います。
お約束
R copy = new R(r.c1(), r.c2(), ..., r.cn()); とやったとき r.equals(copy) が true にならなきゃいけない。ってJavadocに書いてる。
アクセサメソッドやCanonicalConstructorを自分で実装せず生成されるものに任せればいい話。
こんな変なことをするなってことです。(コンパイルは通っちゃう)
record NgRecord(int hoge, int fuga) { NgRecord(int hoge, int fuga) { this.fuga = hoge; this.hoge = fuga; } }
アクセサメソッドで計算してもいいけど、その計算結果をコンストラクタで受けたらアクセサメソッドで同じ値を返すようになってなきゃいけない。
これは「お約束」であって崩せるわけだけど、崩しちゃいけない。equals/hashcodeのように実装するなら意識しとけよってものです。「 equalsが同じになるならhashcodeが同じにならないといけない」ってやつね。
equals/hashcodeよりかは何もしなければ守られるものなので、多少ましかな。似たり寄ったりではあるけど。
今あるのをRecordにする?
無理にする必要はないと思うけど……
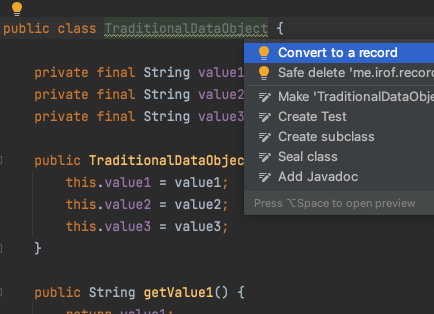
完全コンストラクタを使って全フィールドが final だとIntelliJ IDEAさんは「Recordにしようぜ!」と言ってきます(Weak Warning)。で、サクッと置き換えてくれます。
さすがにアクセサメソッドを置き換えてはくれないので、「recordのアクセサメソッドを使うように置き換えてインライン化」とかはしなきゃな感じ。
自分でツール作ろうと思ったけど、IntelliJ IDEAさんマジIntelliJ IDEAさんだわ。
アノテーションとリフレクション
アプリケーションプログラミングレベルだと特に問題なく使える確信はあります。おそらくイミュータブルなデータコンテナを扱えるかが最大のハードル。 そんなのはRecordに限った話ではないので、気になるのは足回りです。リフレクションとかバイトコードとかです。 バイトコードはどうせJIG対応する時にしっかりみなきゃなので、ここではリフレクションとか、フレームワークやライブラリ目線で。。。
private finalでもsetAccessible(true)したら上書きできるんだけど、recordで作ったクラスだとできない。- リフレクションAPIの中で判定入ってる。
- リフレクションで値をセットしているライブラリはそのままじゃ置き換えられない と言う意味。
- なんとかしてCanonicalConstructorを使うように変更する必要がある。
- Java16以降で対応なら次の
getRecordComponent使えるけど、15以下も同じコードで扱うならそれなりに面倒。
Class#getRecordComponents()とかjava.lang.reflect.RecordComponentとかが追加されてる。Class#isRecord()はRecordかどうかの判定メソッド。親クラスがjava.lang.Recordかとか見てる。
書けるアノテーション
@Target(ElementType.FIELD) public @interface FieldAnnotation { }
と言う感じのアノテーションを全ElementTypeの文作った上でこんなコードを書いて、リフレクションで取ってみるなど。
@TypeAnnotation @TypeUseAnnotation record AnnotatedRecord( @FieldAnnotation @MethodAnnotation @ParameterAnnotation @RecordComponentAnnotation @TypeUseAnnotation int a, int b ) { @ConstructorAnnotation @TypeUseAnnotation AnnotatedRecord { } @MethodAnnotation @TypeUseAnnotation public int b() { return b; } }
@Target(ElementType.FIELD)や@Target(ElementType.METHOD)もレコードコンポーネントのとこに書ける。- これはそれぞれ生成されるフィールドやメソッドに引き継がれる。
- ちなみに
clz.getRecordComponents()*.getAnnotations()では@RecordComponentAnnotationしか取れない。- 他の4つは行方不明。
- コンストラクタのアノテーションを書きたかったらCompact Canonical Constructorsを作る。
recordに@ConstructorAnnotation書いたらいけるかな?とか思ったけどそんなことなかった。
CanonicalConstructorの見分けかた
java.lang.reflect.Constructor からは特になさそう。javap で見えるコンストラクタも特別なフラグとか持ってない。
Class#getRecordComponents() で型を特定してコンストラクタ取るのが確実かな。
var parameterTypes = Arrays.stream(clz.getRecordComponents())
.map(RecordComponent::getType)
.toArray(Class[]::new);
var constructor = clz.getDeclaredConstructor(parameterTypes);
とはいえこれも生成されたのと手で書いたのの区別はつかないわけだけど。 まぁ「お約束」もあるし、名前とか一致してたらいいでしょ。
2021-10-22T23:16 追記 Javadocにまんま書いてた
Class#getRecordComponents のJavadocにまんま書いてあるんですよね……https://t.co/8so72oQzw6()
— がくぞ (@gakuzzzz) 2021年10月22日
ここまでお膳立てしてくれるならutilitiyメソッド標準で用意して欲しさありますね
Class.html#getRecordComponents()
static <T extends Record> Constructor<T> getCanonicalConstructor(Class<T> cls)
throws NoSuchMethodException {
Class<?>[] paramTypes =
Arrays.stream(cls.getRecordComponents())
.map(RecordComponent::getType)
.toArray(Class<?>[]::new);
return cls.getDeclaredConstructor(paramTypes);
}
javadocにメソッド書かず Class にメソッド生やしておいてください(真顔
リフレクションでのインスタンスコピー
CanonicalConstructorの識別がなぜ必要かと言うと、リフレクションで特定のレコードコンポーネントだけ値を変えたインスタンスを作りたいとかなった場合。
- CanonicalConstructorを見つける(上記)
- レコードコンポーネントの値を取得
- 前述の「お約束」があるので、フィールドからでもアクセサメソッドからでもどっちからでも良い。
- けど
private無理矢理見るより、素直にアクセサメソッドかな。
- 必要な値を準備
- CanonicalConstructorでインスタンス生成
って感じかしら。たぶんBeanUtilsかなんかで実装してるのもうあるだろし、そのうち見とこう。。
2021-09-24T10:30追記
リフレクションによるインスタンスコピーはしないで欲しいなー。record側に改修が入った時に追えなくなったりしそう。素直にoptics使うなりLombokのWith使うなり何なりして欲しい。
— がくぞ (@gakuzzzz) 2021年9月24日
余談だけどStreamのとこ
.sorted(comparingDouble(MerchantSales::sales))
の方が好み https://t.co/LsSo8KkM6P
やりたくはないんや……
「各Recordに手を入れず」「一律」となると厳しい感。自分でならwith作るんだけど、目の届かない領域のある開発体制組まれると、どこかで必要になってくる。 そいやLombokはrecordにいい感じのwithを生やしてくれたりするんだろか。
リフレクション関連で思ったこと
フィールドやメソッドにレコードコンポーネントに書いたアノテーションを持ってってくれるのが良い。 これなら既存のアノテーションベースのライブラリもそれなりに素直に対応できるんじゃなかろーか。
Field#set(Object, Object) が accessible = true でも拒否されたのはびっくりしました。
recordじゃないfinal フィールドも蹴るようにしたいけど、そうしたらいろんなライブラリが動かなくなりそうねぇ。
Local record classes
JEPに書いてて面白いと思ったのがLocal record classes。コードを転載。
List<Merchant> findTopMerchants(List<Merchant> merchants, int month) { // Local record record MerchantSales(Merchant merchant, double sales) {} return merchants.stream() .map(merchant -> new MerchantSales(merchant, computeSales(merchant, month))) .sorted((m1, m2) -> Double.compare(m2.sales(), m1.sales())) .map(MerchantSales::merchant) .collect(toList()); }
ローカルクラスなんて使わないよとか昔から思ってたわけですが、これはありな気がしなくもなくもなく。
ちなみにRecordは型パラメーターを持てるので、こんなTupleは書ける。
record Tuple<A, B>(A a, B b) { }
そして「こんなの作らずにちゃんと名前つけようよ!!」って書いてる。
A central aspect of Java's design philosophy is that names matter.
御意。。
ところでjava.lang.Recordクラス
コード見ての通り、equals、hashcode、toString が abstract でOverrideされているだけのクラスです。あとコンストラクタが protected だったりします。
extendsやimplementsはありません。 Serializable も実装していないんだなーそりゃそうかーと見てたら、「実装したら serializable recordとして特別扱いする。具体的にはシリアライズにreadObjectやwriteObjectは使わない」とか書いてるので、もしシリアライズするなら注意がいるかもです。うらがみさんが試してるのでそっち参照。
ところでrecordで生成されるクラス
enumがextends java.lang.Enum になるように、 recordもextends java.lang.Recordになります。
これは Recordに独自の基底クラスを作れない と言う意味になります。あと final にもなるので record で作ったクラスを継承もできません。
Recordの主な用途であるDTOですが、共通項目を基底クラスで宣言して実装継承をしているような用途だと、そのままは代替できません。インタフェースは実装できるのでそちらで共通項目を強制するようなことは可能ですが、レコードコンポーネントは記述する必要はあります。
DTOの実装継承で省力化してたら辛いことありそうですね。
javapのMethodParameters
コンパイルする時に -parameters をつけるとメソッドの仮引数名がクラスファイルに残って、リフレクションとかで使えるようになります。( spring-boot-starter-parentを使ったら有効 になってたりします。)
つけなかったらコンパイル時に消えてリフレクションや javap とかで仮引数名が見えなくなるんですけど、CanonicalConstructorは -parameters をつけなくても MethodParameters が入ってたりします。シリアライズの時に使ってたりするのかな。
思ったこと
素直にDTOの代わりに使うのは思ったよりハードルありそうだなー。

) (English Edition)")