テストでのデータベース単位の捉えかた
データベース(に限らずあらゆる永続化リソース)を使用するテストをいかにして行うかはいつだって悩みの種です。この悩みは「どうやったらデータベースを使用するテストを行えるかわからない」ではなく「なんとかやってるけど、不満のようなものがある」というものになるかと思います。
やりかたはたくさんあるのですが、その優劣は条件なしに比較する意味がないくらい、条件に依存します。どんな選択肢も「この条件なら最適」と言えてしまうだけに、広いコンテキストで「こうするのがベスト」とも言いづらいのです。
前提
- xUnit Test Patterns を下敷きにします。
- ユニットテストでの話です。他でもある程度通じます。
- 具象イメージはSpringBootを使用するWebアプリケーションです。そこまでべったりな内容ではありませんが、背景にあるとご理解ください。他でもそれなりに通じます。
データベースを使用するテストで達成したいこと
テストでデータベースを使いつつ達成したいことはいくつもあります。例を挙げます。
- データベースも含めて期待する動作を担保できること。
- テストが独立していること。
- テストが高速で実行できること。
- テストが繰り返し実行可能であること。
- テストが他のテストと競合しないこと。
- CIで素直に実行できること。
(読み飛ばし可) Independent Testが実現できれば繰り返し実行可能や競合しないは達成できるのですが、完全に独立性させるためにはTransient Fresh Fixtureが必要になってきます。しかしながらテストごとにすべてのFixtureのセットアップが必要になるため、実行速度を損ないます。回避としてShared Fixtureが持ち出されたりしますが、これにより独立性を損ねます。Shared Fixtureを使用したまま独立性を確保するためにDatabase Sandboxを適用しますが、制約が生じて気にすることは増えますし、完全ではありません。
……と言ったことに決着をつけるために、選択肢を把握し、テストしたい対象を見定める必要があると思うんです。もちろん現代のコンピュータースペックを持ってすれば多少効率の悪い方法を選んでも、ある程度はどうにかなります。 どうにかならなくなってから呼ばれるんですよね……
大まかな三分類
細かく分けるときりがないので、今回書きたい内容によって3種類に分類して、それぞれについて書いていきます。
本稿はxUnit Test Patternsを読んでいない方向けとして、以降はなるべくパターン名は控えめで書きます。パターンっぽいところはリンクしておくので、気になる方はそちらをどうぞ。
テストに閉じたデータベース
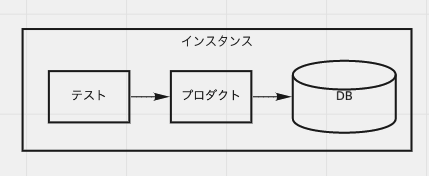
ここでのテストはテストメソッドのイメージです。テストインスタンスがクラス単位ならテストクラス単位でもいいんですが、とにかくテストの実行単位ごとに完全に独立したデータベースを使用します。 図はシンプルですが、テストケース数が100ならデータベース数も100になるイメージです。
すべての情報がテストに閉じている、理想の形です。実現できるならこれでいきたい。
荒唐無稽なことを言っているように感じるかもしれませんが、たとえばH2 Database Engineをインメモリでテストごとに名前を変えれば実現できます。
メリットは何よりも完全な独立性。他のテストの影響でデータがおかしくなってたり、同じデータにアクセスする問題は起こりません。データベース起因のテストの不安定さはほとんど起こりません。並列実行も余裕です。100テストケースを100並列で実行できます。リソースが許せば。
デメリットは大量にリソースを使うことと、準備のコストがそれなりに重いこと。 SpringBootTestだとSpringの起動時間も必要ですし、データベース作成からとなるとかなりのコストになります。 コンテナを使用する場合、セットアップ済みのイメージを使用すれば多少時間は稼げるとはいえ、早くても5秒程度は見なきゃかなと思います(なんか今やったら1秒で起動したけど、多分機嫌がいいんだろう)。5秒かかるものを順番に実行すると、100ケースで500秒かかってしまいます。並列のオプションがあるとはいえ、安易に手を出さずに済ませたいし、1マシンで100コンテナも起動できる気がしない。
H2を使うことに関しては このツイートのスレッド とかで書いてます。今回は書きません。 そのうち別に書くかも。書かないかも。
環境に閉じたデータベース
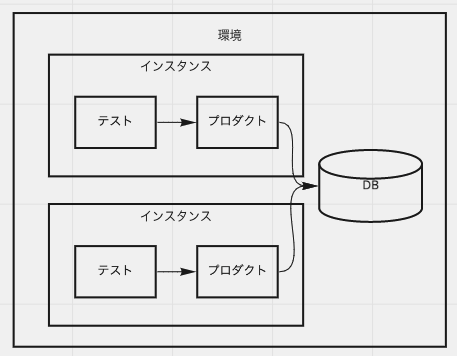
ローカルにデータベースをインストールしたり、その環境専用にコンテナやVMを立ち上げるイメージです。開発環境構築とかで開発マシンにデータベースをインストールしているならこれなので、馴染みあるパターンかと思います。
ここで「環境」と言っているのは、先に挙げたように開発者のマシンとかそういうのになるんだけど、実際は「テストの実行単位」くらいで捉えるのがいいと思います。mvn test とかIDEのテストボタンのクリックとか、そういう単位。「環境」を実行単位とするのは、昨今のコンテナベースのCIだと実行単位ごとにデータベースコンテナを立ち上げられる、あれのイメージです。
メリットはデータベース自体やスキーマ、マスタデータなどがセットアップ済みもしくは単発となるため、その分の速度が見込めること。データベースの動作がイメージしやすいこと。本番とある程度同じデータベースが使用できることなどが挙げられます。
デメリットは複数のテストでデータベースを共有していることによるもの。かなり注意していても他のテストの影響でテストが落ちたりしがちです。共有するFixtureがすべて不変ならいいのですが、そうとも限りません。また、テストでセットアップするデータも永続化されるため、後片付けが必要になります。 もしかしたら「開発者がデータベースをセットアップする必要がある」がデメリットになるかもしれません。
「ちゃんと後片付けすれば問題ない」と言うのは全てのコードが制御下にあり、順調に動いている時のみ言えることです。アプリケーションの機能が豊富になってくると「テストで参照していないテーブルへの更新」などがあり、面倒が見切れないこともしばしばありますし、後片付け時の接続断やVMクラッシュなどで必ずいつか失敗して不正なデータが残り、後のテストを阻害します。想定しておく必要はあります。 トランザクションを使用してある程度は担保できますが、テスト対象がトランザクション制御をしていたら適用は難しくなりますし、テスト後のデータを確認したい(と思うのはテストに対するスメルなんですが、思うの自体は仕方ない)こともあり、コミットしたくなったりもする。
このパターンでは、テストの実行順が変わったり並列実行すると不具合がでることもしばしばあります。気をつけていても起こると思いますし、原因を見つけても「事後処理の漏れ」と言う非生産的な対応となるため、あまり嬉しくありません。
開いたデータベース
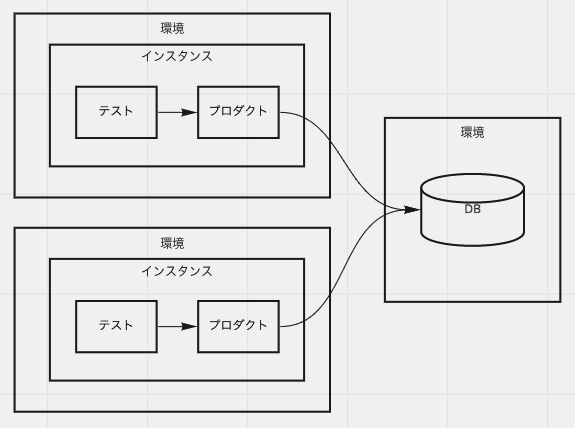
環境に一つどころか全体で一つのデータベースを用意し、それを共有するパターンです。 実行単位でデータベースを起動できない場合、CIではこの形になったりします。 ローカルマシンが貧弱だったころは開発環境でもよく見ました。いまはあまり見ません。見ないとは言わない。
メリットは何よりデータベースのセットアップコストが低いこと。準備は誰かがすればよく、テスト実施側は動いてるサーバーに接続するだけなので、起動すら不要です。 インメモリデータベースや開発環境にインストールする代替データベースではなく、本番相当のスペックや設定のデータベースが使用できうることもメリットに挙げられるかもしれません。(「できうる」です。実際は費用面などからダウングレード版を使うことになるでしょう。)
環境ごとにスキーマを用意するなどすれば環境ごとと同程度の独立性は得られますが、一部のメリットを損ねるのと、接続する可能性のある環境の数だけスキーマが必要になります。また、複数スキーマを使ったデータベース設計を行っていると適用は難しくなります。これは CREATE DATABASE を行えるようなデータベース製品なら緩和できる可能性はありますが、できないものもあるのでいつも使えるわけではありません。
デメリットは「環境に閉じたデータベース」のほとんどが強化されて乗っかってくるのに加え、他の環境から不意に触られるリスクを抱えることになります。 また、共有するデータを変更する場合、多方面に調整が必要になったりするかもしれません。
前段のように環境ごとにデータベースを用意する場合、同じテストを同時に実行することはそんなにありません。ですがこの形だと複数人が同じテストを実行する、CIのコミットステージが同時に動作する、などで全く同じテーブルの同じデータを更新することもまま出てきます。トランザクションを使用していると予期せぬロックでテスト実行時間が妙に伸びたり、使用しているデータベーステスト補助ライブラリなどによってはデッドロックが生じることもなくはありません。「CIが落ちた原因が誰かが同じタイミングでテストを実行したから」とか、わかってもつらみしかありませ。実行した人が責められたりとか……意味わからない。 こう言うことに煩わされたくないので、私はこのパターンの採用にはかなり抵抗しています。でも仕方ない時もある。
また、ユニットテストにおいては通信が必要なところも無視できません。通信不調の影響を受けますし、通信時間も要します。同じネットワーク内の通信であることが多いのでそこまで通信時間はかかりませんが、ユニットテスト文脈では0.1秒かかると10,000ケースのテストで1,000秒プラスでかかります。こんなことを理由にユニットテストのケース数を抑える努力はしたくないものです。そしてこう言うテストに限って並列耐性がなかったりします。
昨今の焦点はCI
開発環境は「環境に閉じたデータベース」でどうにかなってきました。CIでどう考えていくかが現代の焦点になるかと思います。 CIも多くがコンテナが前提になってきているかと思います。10年前は「CIサーバー環境に依存したビルド」なんてものがちらほらありましたが、ほとんどがコンテナによって制御できるようになってきて、とても良い。
さて、CIでテストするにあたり「テストに閉じたデータベース」であればそもそも外因に左右されないので気にする必要はありません。 気にする必要がないのでこれは置いておきましょう。実現できる文脈がまだ限られる話でもありますし。
と言うことで、先に「環境に閉じたデータベース」で書いたように、実行単位ごとに独立したデータベースが欲しくなります。 そしてCIサービスはこれに応えていて、CircleCIではセカンダリコンテナでデータベースを使うとか、GitHub Actionsでサービスコンテナを使うとかが使えるかと思います。CIとしては持っていて欲しい機能になってきていますが、なくてもDocker in Dockerなどで対応できることもあります。そこまでしてでも「環境に閉じたデータベース」を用意する価値はあります。
とはいえ、データベースコンテナを使用するとコンテナ数が単位ごとに一つ追加になります。CIサービスでは使用できる枠に制限がありますし、自前であってもマシンリソースが厳しくなってきます。いつだって取れる選択肢ではないかもしれません。テストに対してデータベースは補助的なものなのに、それのせいでテストの実施が心理的/経済的に妨げられるのはあまり嬉しくないです。
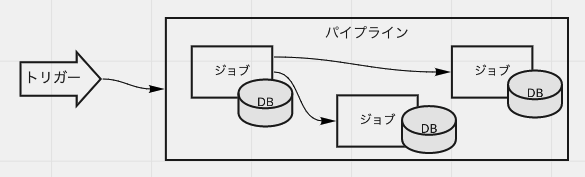
「テストに閉じたデータベース」が厳しくても、環境(ジョブ)の実行ごとに閉じて欲しい。それが厳しいならせめてパイプラインの実行ごとに閉じたデータベースが欲しいところです。
「環境に閉じたデータベース」が選択できず、やむを得なく「開いたデータベース」を使用することもあるでしょう。 データベースサーバーやデータベースアプリケーションは共有しても、テストごとに独立したデータベースやスキーマを作って擬似的に「環境に閉じたデータベース」が作成できることもあります。可能ならばこれを選ぶのが良いでしょう。
やむを得ず共有したデータベースをそのまま使用することもあります。CIにおいてこれはすごく厄介で、同時実行を制限しなければならないかもしれません。CIサーバーでは同時実行数制限などを行えたりしますが、どの単位で制限するかで、CIからのフィードバックの速度が格段に変わります。 もし一連のテストに1時間かかり、データベースを占有しなければ不安定になるとしたら、5個トリガーすれば結果が見れるのは翌日です。こんなのでは「継続的」と言うのは厳しくなってきます。
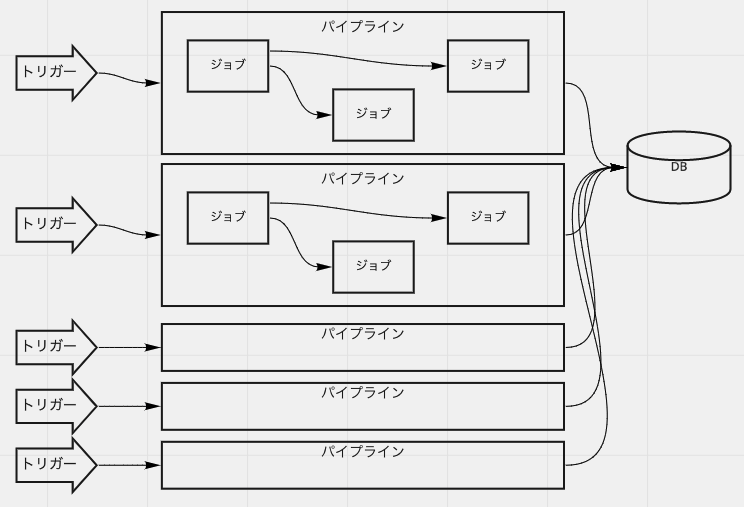
パイプラインの実行が他のパイプラインで妨げられるのは嬉しくありません。同じパイプラインであればトリガーを順次実行でも「仕方ないなー」と思えるかもしれませんが、他のパイプラインもまたがっては厳しいです。シンプルな単一アプリケーションではあまり考えづらいかもしれませんが、複数のアプリケーションが連携するシステムにおいて、アプリケーションがデータベース共有で連携されるパターンだとあり得る話です。
CIでは「全く同じテストが同時に実行される」はザラにあります。 この際に問題にならないように設計するには、データベースを可能な限りテスト、悪くても環境に閉じるように作るよう、努力をする必要があります。 どうにもならず同期する前に、同じデータベースを使いつつ閉じたデータベースを実現する足掻きもする価値はあります。
xUTPのターン
ここはパターンを使います(我慢できなかった)
) (English Edition)")
データベースを使用するテストでは、Database Sandbox をいかに実現するかが勝負かなと思っています。 意図したデータで意図したテストをする、そのために意図しないデータが紛れ込まない、紛れ込ませない技術が重要。
xUTPの時代背景上、開発者などが最小単位になっていますが、先に挙げたように「テストケースごとに独立」が可能なら実現したいことです。 これがデメリットなしに実現できるのが理想のスタートライン(ここで語っているのはテストの準備段階であり、あくまでスタートラインなんです。やりたいことはテストなんです。)、他の全てはいかにこれに近づけるかの妥協です。
コンテナ時代の到来により、Dedicated Database Sandboxが実現しやすくなりました。CIでも使っていきたいですが、CIサーバーのリソースによっては制限を加える必要が出てきます。
DB Schema per TestRunnerは「環境を跨いでデータベースを共有」せざるを得ない時に有用です。もしかしたらDedicated Database Sandboxの場合もテストの並列実行を考慮するとありかもしれません。
Database Partitioning SchemeをGenerated Valueで実現すれば、データベースを共有していても後片付けが不要になったりもします。これは多くのアプリケーションではそんな難しいことでもなく、アプリケーションがたいてい持っている「一意キーを発行する機能」を使うだけで済むものです。アプリケーションとデータベースの設計にもよりますが。データベースに大量のテスト後データが残ったりもしますが、そもそもアプリケーションはデータが溜まっていくものでしょう。何かしら対処する機能はあるはずですし、クリーニングもそこまで難しいものでもないはずです。
Fresh Fixture、できればTransientを第一において、少しずつ崩していく。Shared FixtureにするにしてもImmutable Shared Fixtureを見定めて適用し、mutableには安易に手を出さない。そしてFixtureのSetUpは適切なFixture Setup Patternを選ぶ。SetupしたならTearDownも必要で、対応する適切なものを選ぶ必要がある。そしてTearDownは失敗するものとして備えておく(データベースに限った話ではないが)。
先に書いた「テストに閉じたデータベース」はTransient Fresh Fixtureなんですが、「データベースの準備も含めてテストが行う」は一見非効率に見えて利点はものすごくたくさんあります。最大の利点はIndependent Testが採用するだけで達成できること。そしてオンメモリになるので実行速度はディスクやネットワークアクセスと比べるまでもありません。TearDownも不要であり、仕組みがシンプルになります。「データベースを起動しわすれて動かない」とかも起こり得ません。「実行すれば実行できる」と言う単純なことがバックエンドサービス(12factor)に依存するテストでは難しくなるのですが、それに煩わされない取り回しの良さは強力です。読めば必要なものがわかるのでTests as Documentationにも貢献できます。いつもセットアップするからと言ってImplicit Setupで隠しちゃうと見えなくなるので、併用には注意が必要ですが。
他にもデータベースのテストではPrebuilt FixureやStandard Fixture、Shared FixtureのLazy Setupなどもよく出てきます。 データベーステストを補助するライブラリを使用していると知らず知らずのうちに使っていたりします。そういう目で見ると「このパターンの実装(卵と鶏の関係だったりする)だから、こういう使い方」みたいなのが見えてきて面白かったりもします。
xUnit Test Patternsのほとんどは2000年代の初めであり、私が ファッションで 持っている本も2007年に印刷されたもの。
20年も前ですが、パターンとしてはまだまだ学ぶ価値があるものなんじゃないかなと思ってます。
この辺りの語彙で会話できるととても話が早いですし。
まとめ
全部xUnit Test Patternsに書いてた。
補足: 2021-09-23
最初に「比較する意味がない」と書いてる通り、どれがいいとかではないです。と言うか自動テストあるプロダクトなら、たぶん全部あります。意識の度合いはまちまちでしょうが、使い分けてるはずです。
そもそも「テスト」の分類すら曖昧です。単体試験がどうとかユニットテストがどうとか、結合って何と何の結合だとか。一般的に受け入れられるラベリングはありますが、それが全ての現場に当てはまることはありません。脱線が過ぎた。ともかく、「メソッドがテスト対象となるユニットテスト」を切り出しは基本の整理に役立ちますが、現場に適合させる際は応用が必要になります。なのでxUnit Test Patternsを下敷きにしているものの、本稿のタイトルは「テストでの」と広く取りました。
本稿は、これくらいは意識して識別するとだいぶやりやすくなるんじゃないかな?を狙ったものです。現場の状況にもよりますが、実際はもっと細分化して取捨選択しますし、他のTestFixtureとの絡みもあります。それらはもっと特定技術要素に寄ったものになり、理解のための前提知識が特化したものになっていきます。技術以外の要因で切り捨てるものもあります。その辺りは現場でやっていきたいところです。(遠回しな営業活動)
あと、一度「これで」と決めて進めていても、途中で切り替えるとかもザラにあります。切り替える時、に「開いたデータベースをこの環境に閉じるようにしよう」みたいに意識してパスを通しておくと、それに伴う作業内容やリスクがノウハウとして溜まります。次以降スムーズにいくようになります。これがパターンの力であり、プログラミングに通じるところがある。と思ってたり。
Java17雑感
LTSとなるJava17が出ました。組織が今後もJavaを使っていけるかの試金石になるバージョンだと思います。
実際のとこLTSだから特別安定してるとかそんなことはないと思うし、6バージョン(3年)ごとにLTSにするってのもたぶんOracleさんが言ってみただけで、いろんなとこがそれに乗っかってるから、実質的に節目になってるに過ぎない。はず。 その程度のものなんだけど、私のようなのは乗っかりますし、たぶん多数派なんじゃないかなぁ……この派閥が運用で使うJavaのバージョンは8、11、17で、他のバージョンは評価に使うくらいでしょう。
11から17のジャンプになるんで、かなりたくさんの変更がありますが、業務アプリケーションの表層に関係するものはそこまで多くありません。パフォーマンスとかに影響のあるものは多々ありますが、基本的には早くなるはずで、問題になることは稀です。稀なことはよくあるんですが。
ということで、17にした時に業務アプリケーションの表層に影響のありそうなものを挙げて雑感を書いておきます。多分3ヶ月後くらいにはいうこと変わりますが。 JEPの名前とリンク、正式版として導入されたバージョンです。
- Text Block: JEP 378, Java15
- Switch Expression: JEP 361, Java14
- switch式です。
if式が欲しい - なんかswitchの強化多いんですよね。11以前はswitchなんて滅多に使わなかったけど、今後は見る機会が増えてくるかもしれません。
- とはいえ無理に使わなくてもいいと思います。いい感じに書けそうなら試す、くらいで。
- switch式です。
- Record: JEP 395, Java16
- 目玉。Java17を採用するなら使っていきたいかなーと。
- 私がよく見る「lombokを使いたい動機」のほとんどが消えます。Data以外にBuilderとか使い倒してたら引き続き出番はありますが。
- イミュータブルの強要、アクセサのメソッド名にgetがつかない、バインディングライブラリの対応状況など、地味なハードルはあります。
- とは言え無理に使わなくてもいいと思います。recordでなければできないことも今はないだろし。
- 2021-09-24追記: Recordを使ってく上で気にしとくこと 書いた。
- Sealed Class: JEP 409, Java17
- 他言語によく(?)あるSealedClassがJavaにもやって来ました。
- 挙げてはみたものの、今後の準備として入った程度の認識で良いかと。
- 使い方がこなれて、これを利用するものが増えてきてからでいいと思います。
- Pattern Matching for instanceof: JEP 394, Java16
- instanceofの後のキャストを書かなくて良くなります。
- ジェネリクス以降登場機会の激減したキャストさんの活躍場所がまた減った。
- 挙げてはみたものの、そもそもinstanceofを使う機会が少ないし、無理に使う必要は無いかと。
- 使える場面では喜んで使えばいいと思います。一行減るだけだけど。
五つだけ。まとめると「TextBlockをテストで使って、データクラスを新しく作るならRecordを使ってみる」くらいでしょうかねぇ。
コーディングにそう影響ないから挙げてないけど、個人的に一番嬉しいのはHelpful NullPointerExceptionsだったりします。下手にnullチェックして例外投げるくらいなら、チェックせずそのままNPE発生させる方が役立つ可能性まである気がしてたり。
細かいけど嬉しいの
String#formattedJava12Stream#toListJava16Collectors#teeingJava12
ちょっと便利系。この辺のAPIはIDEが教えてくれるから、存在自体を知らなくても、使う機会が来たら使えると思います。
実際いつあげんの
- プロダクトはSpringBootがほとんどなんで、来週出るらしいJava17対応のSpringBoot2.5.5に乗っかる。
- 2021-09-24追記: Spring Boot 2.5.5 available now 出た。特別に17向けの何かはないけど、まぁ動いてる。
- その頃にはbuildpackも出るだろから乗っかってないのもいけるかなって。
- Java16で動かしてるものは軽い気持ちでコンパイルから全部17にあげる。
- Java11のは検証環境のランタイムだけ17にしてしばらく回してから。
そんな感じ。
まともな情報
- きしださんとこ の「Java XX新機能まとめ」シリーズ
- さくらばさんとこの「JEPでは語れないJava XX」シリーズ
- てらださんのJEP一覧
とりあえずSpringBootアプリケーションをherokuで公開する
手順の全て
mkdir {てきとうななまえ}cd {てきとうななまえ}curl -O https://start.spring.io/pom.xml -d dependencies=web -d javaVersion=8- Applicationクラス作成(後述)
git initgit add .heroku createheroku git:remote -a {createで作られたもの}git push heroku main
9ステップ。これでgit pushのレスポンスメッセージに出てるURLにアクセスしたらhelloと表示されます。目指せ5分!
説明
書きたいところを適当に書いていきます。あ、herokuアカウントの作成とコマンドラインツールのインストールは済ませといてください。私はbrewで入れてます。
この記事は現在に対する局所最適なので、バージョンなどは割愛します。 未来にこの記事のバージョンに合わせて動かすより、やりたいときにその時点での最新のやり方でやるのがいいと思います。 どうせherokuの挙動変わったらバージョンなんぞ合わせられないし。
curl...
Spring Initializr です。ブラウザでも使えますけど私はもっぱら curl で叩いてます。
詳しくは SpringBootのプロジェクトを作成する - 日々常々 とか。
普段はGradle使っていますが、今回はMavenを選択。
これは plain jarがSpringBoot2.5からできるようになって、herokuのデフォルトだと *.jar で起動しようとしてエラーになるため。
無効にするとかexecutable jarを実行するように明示するとかすればいいんだけどステップが増えるので今回は回避しています。
-d dependencies=web はこれがないとウェブアプリケーションにならないので。(webflux でもいいんだろけど)
-d javaVersion=8 がポイントでherokuのデフォルトJavaバージョンは1.8だったりします。SpringInitializrデフォルトは11なんで、そのままじゃ動かない。
pom.xmlを修正したり、system.properties(herokuが読む設定)に java.runtime.version=11 とか書いてもいいんだけど、今回は一番ステップが少なくなるの選びました。
普通は system.properties 書くことになると思います。書けばJava16も使えるよ。実際いくつかで使ってたりします。
Applicationクラス作成
コマンドだけで無理やり作るとこう。
% mkdir src/main/java/hoge
% cat>src/main/java/hoge/Application.java
package hoge;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.bind.annotation.RequestMapping;
@SpringBootApplication
@RestController
public class Application {
public static void main(String[] args) { SpringApplication.run(Application.class, args); }
@RequestMapping
String index() { return "hello"; }
}
1クラスとはいえIDEで書くのがなんだかんだで早いと思う。importとか書いてられん。
(とはいえIDEで書くと後の git add . が . じゃ余計なものが入るので pom.xml と Application.java だけaddしなきゃになって若干面倒にはなる。些細な問題だけど。)
@Controller でなく @RestController なのはハンドラメソッドの戻りで文字列を直接返したいから。@Controllerだとテンプレート探しに行ってエラーになって /error なくて404になっちゃう。@ResponseBody とか書けばいいんだけど面倒だから @RestController にしちゃった。
あとデフォルトパッケージにすると余計なものコンポーネントスキャンで食っちゃうので、適当でもいいんでパッケージはつけなきゃです。
heroku create
ログインしてないとこれ叩いたときに自動でログイン促されます。ブラウザが開く。
heroku create は apps:create の短縮。アプリ名を渡せるけど、指定しなかったら適当につけてくれる。今回はお任せ。
![]()
これだと salty-woodland-12925 ですね。(destroy済み)
次の heroku git:remote は git remote add heroku {herokuのgitのURL} を代わりにやってくれるコマンドです。git コマンドを叩いても一緒なんでお好きな方でOK。gitのURLもcreate 時に出てますしね。
ここに push したらherokuはビルドして動くようにしてくれます。
git push
ソースコードを投げ込むといい感じにビルドしてくれるのがbuildpack。
「pom.xmlがあるからMavenだろ」「SpringBootだからこうだろ」みたいなのを雰囲気でやってくれます。
雰囲気でやってくれすぎて何がどうなってるか分からなくなる可能性がそこそこ。
わかりたかったら https://buildpacks.io/ とかで pack コマンド使って手元でビルドして docker run とかいじってみると、何かわかるかもしれない。わからないかもしれない。
git push したらMavenのいつものjarダウンロードのログがダラダラ流れる。git push でそんなん表示されるのに慣れてないと面食らうかもですね。
成功したらこんな感じ。

Released とかの次の行の https://... を開いたら動いてる。はず。
今回はherokuのgitにpushしたけど、普段はGitHubからherokuに繋いで使ってます。この辺の連携も素直につながるのでいいですよね。
あとがき
適当にやろうとしたら地味なつまずきかたをしたので整理してみました。 ビルドは3分くらいで終わるんで、スムーズにできれば「ゼロから始めて5分でデプロイ完了」までいけると思います。ドラが鳴る前に終わることを祈る。
今回つまづいたのは
*-plain.jarのおかげでGradleだと素直に動かない。build.gradleのjarタスク止めるか、Procfile(herokuの設定ファイル)で動かすJar名を明示したらいける。普段は後者でやってる。
- デフォルトJavaバージョンの食い違い
pom.xmlとかbuild.gradleのバージョン読んでくれるようにきっとそのうちなると信じてる。
……くらいかな? こういうの踏んだときに雰囲気で察しちゃったりするんだけど、「ここにこのログが出てる」と確認しておくのも大事で、そういうのがこの手の素振りの目的だったりもします。
herokuでMaven使った記憶はないんだけど、「どうせいけるだろ」みたいなノリで push したらいけました。よかったよかった。
この「どうせいけるだろ」みたいな感覚って結構大事だと思ってたりします。たまに大外しするけど。
追記: タイムアタック結果
- start:
2021-08-05T11:20:11 - finish:
2021-08-05T11:22:08
コマンドのみの一発勝負。1分57秒でした。 mkdirから最後にcurlでhelloが返って来るところまで(curlのhello確認は上の手順にないですが。)で、全ログは gist に置いてます。 少し上で「ビルドは3分」とか書いてますが、herokuのご機嫌によりますね。
…… git init がReinitialized になってるな。空じゃなかったのか。🤔
似た記事
「ソースコードの公開まで」って感じですね。今回のは手元の動作確認すらしてないという・・・。